Paper Authors and Title
Adrien Dudon (South East Technological University), Oisin Cawley “A comparison of Convolutional Neural Networks and Vision Transformers as models for learning to play computer games”
Abstract
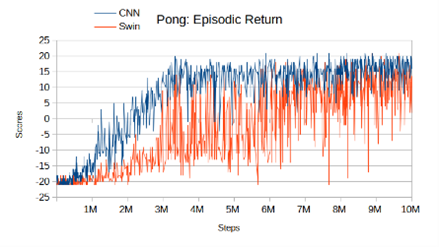
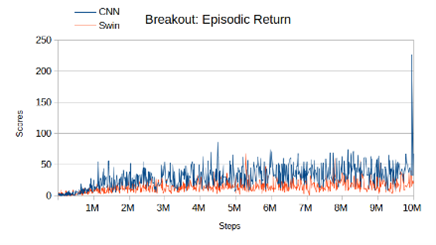
The integration of the Convolutional Neural Network (CNN) architecture with the Double Deep Q Network (DQN) algorithm has been extensively employed in resolving intricate video game environments, particularly within the domain of Atari games. Nevertheless, the emergence of Vision Transformer (ViT) architectures has demonstrated superior performance in various tasks previously dominated by CNNs. This research seeks to replicate the study conducted by Meng et al. in 2022 and assess whether the Swin Transformer, a variant of ViT, can effectively learn to play video games and achieve comparable results within fewer training steps, compared to CNN. We experimented with two distinct games, namely Pong and Breakout. Although we know that CNN can give honourable results, this research seeks to improve these results further and assess the potential of ViT for the future in more complex games. Double DQN is traditionally used with CNN as its main backbone, in this study, we replaced CNN with Swin Transformer.
The study’s findings reveal that the Swin Transformer architecture demonstrates notable performance; however, the CNN architecture outperforms it under 10 million training steps. In our results, Swin seems to learn more slowly and therefore does not begin to converge until later in the process. Additionally, the CNN architecture proves to be more computationally efficient, requiring less computing power and functioning optimally on older hardware while consuming a reasonable amount of memory. To surpass CNN performance, the Swin Transformer necessitates a substantial number of training steps, in support of Meng et al.’s study.